

发布时间: 2019-09-19 10:12:28
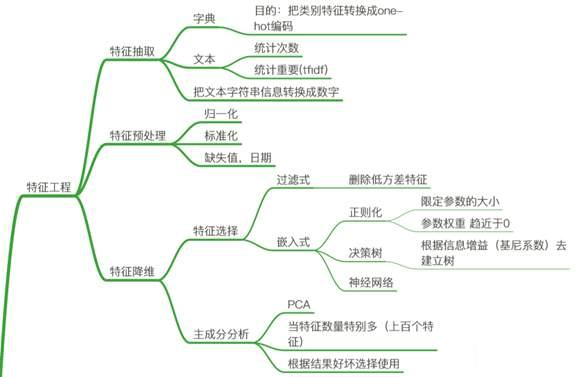
特征是数据中抽取出来的对结果预测有用的信息,可以是文本或者数据。特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。过程包含了特征抽取、特征预处理、特征选择等过程。
sklearn是机器学习中一个常用的python第三方模块,网址:http://scikit-learn.org/stable/index.html ,里面对一些常用的机器学习方法进行了封装,在进行机器学习任务时,并不需要每个人都实现所有的算法,只需要简单的调用sklearn里的模块就可以实现大多数机器学习任务。
机器学习任务通常包括特征工程、分类(Classification)和回归(Regression),常用的分类器包括SVM、KNN、贝叶斯、线性回归、逻辑回归、决策树、随机森林、xgboost、GBDT、boosting、神经网络NN。
常见的降维方法包括TF-IDF、主题模型LDA、主成分分析PCA等等
以下特征工程使用sklearn来实现
数据准备包括数据采集、清洗、采样
1,数据采集:数据采集前需要明确采集哪些数据,一般的思路为:
- 哪些数据对最后的结果预测有帮助?
- 数据我们能够采集到吗?
- 线上实时计算的时候获取是否快捷?
2,数据清洗: 数据清洗就是要去除脏数据,就是对有问题的数据进行预处理。(在特征处理的时候会对空值等进行处理,这里主要是对一些不合理的数据先处理掉,比如一个有33天),* 常用的异常点检测算法包括*
- 偏差检测:聚类、最近邻等
- 基于统计的异常点检测:例如极差,四分位数间距,均差,标准差等,这种方法适合于挖掘单变量的数值型数据。全距(Range),又称极差,是用来表示统计资料中的变异量数(measures of variation) ,其较大值与最小值之间的差距;四分位距通常是用来构建箱形图,以及对概率分布的简要图表概述。
- 基于距离的异常点检测:主要通过距离方法来检测异常点,将数据集中与大多数点之间距离大于某个阈值的点视为异常点,主要使用的距离度量方法有绝对距离 ( 曼哈顿距离 ) 、欧氏距离和马氏距离等方法。
- 基于密度的异常点检测:考察当前点周围密度,可以发现局部异常点,例如LOF算法
3,数据采样:采集、清洗过数据以后,正负样本是不均衡的,要进行数据采样。采样的方法有随机采样和分层抽样。但是随机采样会有隐患,因为可能某次随机采样得到的数据很不均匀,更多的是根据特征采用分层抽样。
就是从原始的数据中构造特征集,原始数据可能是时间戳、文本、图片、音频等。我们需要从这些数据中构建特征集
对于类别型数据不能用数值表示。(比如颜色{红、绿、蓝},数字1、2、3可以表示,但是颜色本身没有数学关系,这会误导我们的数学模型)。常用的方法是热编码-(one-hot方法)(OneHotEncoder类)
|
(1)词袋:本数据预处理后,去掉停用词,剩下的词组成的list,在词库中的映射稀疏向量。Python中用CountVectorizer处理词袋。 也就是考虑某个词在当前训练样本中出现的频率。
(2)使用TF-IDF特征:TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF(t) = (词t在当前文中出现次数) / (t在全部文档中出现次数),IDF(t) = ln(总文档数/ 含t的文档数),TF-IDF权重 = TF(t) * IDF(t)。自然语言处理中经常会用到。(考虑到了这个词语是不是在大部分文件都出现了,即包含这个词语的文本条数的倒数,这种词语一般没有什么作用,排除掉常用词语的干扰)
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer import jieba import numpy as np import pandas as pd def cutwords(): ''' 计算词的重要性 ''' def tfidvec(): c1, c2, c3 = cutwords() tv = TfidfVectorizer() data = tv.fit_transform([c1,c2,c3]) print(tv.get_feature_names()) print(data.toarray()) return None |
归一化方法有两种形式,一种是把数变为(0,1)之间的小数,一种是把有量纲表达式变为无量纲表达式。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速,应该归到数字信号处理范畴之内。
min-max标准化(Min-max normalization)/0-1标准化(0-1 normalization)
也叫离差标准化,是对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下:

注:作用于每一列,max为一列的较大值,min为一列的最小值,那么X’’为最终结果,mx,mi分别为指定区间值默认mx为1,mi为0
from sklearn.preprocessing import MinMaxScaler,
|
通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内

from sklearn.preprocessing import StandardScaler
|
对于缺失特征可以修改成新的特征,也可以删除,常用有:
(1)删除:最简单的方法是删除,删除属性或者删除样本。如果大部分样本该属性都缺失,这个属性能提供的信息有限,可以选择放弃使用该维属性;如果一个样本大部分属性缺失,可以选择放弃该样本。虽然这种方法简单,但只适用于数据集中缺失较少的情况。
(2) 统计填充:对于缺失值的属性,尤其是数值类型的属性,根据所有样本关于这维属性的统计值对其进行填充,如使用平均数、中位数、众数、较大值、最小值等,具体选择哪种统计值需要具体问题具体分析。另外,如果有可用类别信息,还可以进行类内统计,比如身高,男性和女性的统计填充应该是不同的。
(3) 统一填充:对于含缺失值的属性,把所有缺失值统一填充为自定义值,如何选择自定义值也需要具体问题具体分析。当然,如果有可用类别信息,也可以为不同类别分别进行统一填充。常用的统一填充值有:“空”、“0”、“正无穷”、“负无穷”等。
(4) 预测填充:我们可以通过预测模型利用不存在缺失值的属性来预测缺失值,也就是先用预测模型把数据填充后再做进一步的工作,如统计、学习等。虽然这种方法比较复杂,但是最后得到的结果比较好。
from sklearn.preprocessing import Imputer import numpy as np
|
很多任务与时间维度有关系,比如用电量等,此时要将时间戳数据转换为时间特征。常见的转换有:
(1)day of weak(一周的星期几)、day of month、day of year、week of year、month of year、hour of day、minute of day 、哪个季度。
(2)t_m24(前一天的数值)、t_m48(前两天的数值)等。
(3)tdif(与亲一天的数值的差值)等。
当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。原始的特征可能有冗余(两个特征说的是一个问题,相关性太强)、噪声(会影响问题的效果)。通常来说,从两个方面考虑来选择特征:
特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
1,filter(过滤法):方法:评估单个特征和结果值之间的相关程度, 排序留下Top相关的特征部分。 评价方式: Pearson相关系数, 互信息, 距离相关度。 缺点:只评估了单个特征对结果的影响,没有考虑到特征之间的关联作用, 可能把有用的关联特征误踢掉。因此工业界使用比较少。
(1)方差选择:计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。使用feature_selection库的VarianceThreshold类。
(2)相关系数法:计算各个特征对目标值的相关系数以及相关系数的P值。用feature_selection库的SelectKBest类结合相关系数来选择。
(卡方检验是检验定性自变量对定性因变量的相关性,互信息是评价定性自变量对定性因变量的相关性,可以用这两个值和SelectKBest类来选择)
2,wrapper(包裹法): 方法:把特征选择看做一个特征子集搜索问题, 筛选各种特 征子集, 用模型评估子集特征的效果。 典型算法:“递归特征删除算法”,应用在逻辑回归的过程:
a.用全量特征跑一个模型;
b.根据线性模型的系数(体现相关性),删掉5-10%的弱特征,观察准确率/auc的变化;
c.逐步进行, 直至准确率/auc出现大的下滑停止。
(python中是RFE类)
3,嵌入法: 方法:根据模型来分析特征的重要性,最常见的方式为用正则化方式来做特征选择。(这种方式在工业界很常用)
(1)基于惩罚项的方法:就是用L1,L2正则化来做特征选择。L1正则有截断效应:不重要的特征的参数权重为0,L1正则方法具有稀疏解的特性,因此天然具备特征选择的特性,但是要注意,L1没有选到的特征不代表不重要,原因是两个具有高相关性的特征可能只保留了一个,如果要确定哪个特征重要应再通过L2正则方法交叉检验;;L2正则有缩放效应:拿到手的特征都比较小。SelectFromModel类来解决。
(2)基于树模型的特征选择法:树模型中GBDT也可用来作为基模型进行特征选择,使用feature_selection库的SelectFromModel类结合GBDT模型。
from sklearn.feature_selection import VarianceThreshold
|
当特征选择完成后,可以直接训练模型了,但是可能由于特征矩阵过大,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。常见的降维方法除了以上提到的基于L1惩罚项的模型以外,另外还有主成分分析法(PCA)和线性判别分析(LDA),线性判别分析本身也是一个分类模型。PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样: PCA是为了让映射后的样本具有较大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。PCA和LDA降维原理涉及到大量的数学推导过程,请自行查阅相关文档
from sklearn.decomposition import PCA
|
上一篇: 思科认证更新常见问题FAQ

微信

公众号











