

发布时间: 2019-08-30 16:24:30
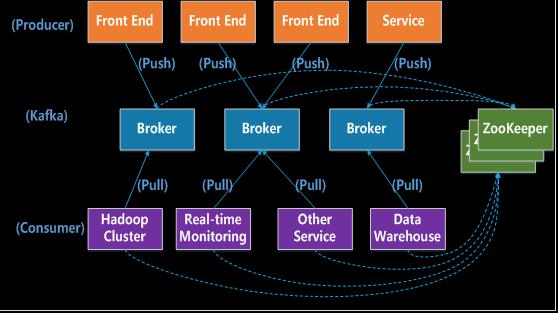
Kafka和其他组件比较,具有消息持久化、高吞吐、实时等特性,适用于离线和实时的消息消费,如网站活性跟踪、聚合统计系统运营数据(监控数据)、日志收集等大量数据的数据收集场景。

Consumer:消息消费者,从Kafka Broker读取消息的客户端。
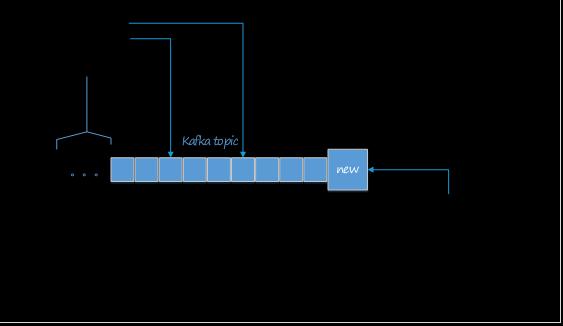
图片中的蓝色框为Kafka的一个Topic,即可以理解为一个队列,每个格子代表一条消息。生产者产生的消息逐条放到Topic的末尾。消费者从左至右顺序读取消息,使用Offset来记录读取的位置。
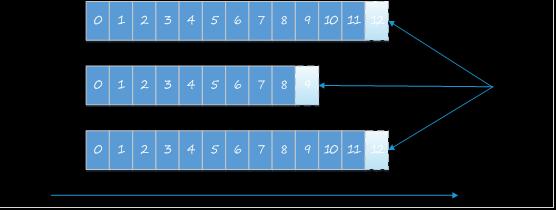
Kafka Partition
每个Topic 都有一个或者多个Partitions构成。每个Partition都是有序且不可变的消息队列。引入Partition机制,保证了Kafka的高吞吐能力。引入Partition机制,保证了Kafka的高吞吐能力,因为Topic的多个Partition分布在不同的Kafka节点上,这样一来多个客户端(Producer和Consumer)就可以并发访问不同的节点对一个Topic进行消息的读写。
上一篇: Java培训_SpringCloud构建模块化工程实现全局版本控制
下一篇: 人工智能AI培训_中文文本分词

微信

公众号











