

发布时间: 2019-08-29 13:43:18
对中文分词框架jieba当中的分词模块有相应的了解,主要是对分词函数及其相应参数有所了解。
4.安装相关模块
安装jieba分词模块。点击windows系统左下角的“开始”按钮,进入菜单列表:
图1-1Anaconda Prompt
点击“Anaconda Prompt”按钮,进入Anaconda系统:
图1-2Anaconda 环境
两种安装安装方式,基于Anaconda的conda install jieba和基于Python的pip install jieba,两种都可以使用,操作如下: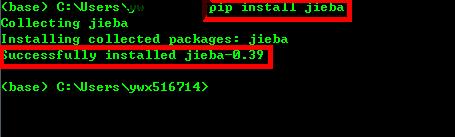
图1-3安装jieba
同样的操作流程,其他需要的Python框架安装也是如此。
5.实验步骤
本章内容包括4个小操作,都是基于jieba分词进行操作,其中结巴分词包括三种分词模式,下面就进行一一演示。具体如下:
jieba的精确分词模式实现;
jieba的全分词模式实现;
jieba的搜索分词模式实现;
基于jieba的文本分词实现;
5.1.精确模式分词
代码:
# 导入模块
import jieba
import warnings
# 忽略警告
warnings.simplefilter('ignore')
# 精确模式
print("----精确模式:----")
# 分词语料
s = u'华为合作伙伴网络是华为与合作伙伴之间的协作框架,包含一系列的合作伙伴计划。'
# 精确分词
cut = jieba.cut(s, cut_all = False, HMM=False)
print(' '.join(cut))
结果:
----精确模式:----
华为 合作伙伴 网络 是 华为 与 合作伙伴 之间 的 协作 框架 , 包含 一系列 的 合作伙伴 计划 。
5.2.全模式分词
代码:
# 全模式
print("----全模式:----")
# 全模式分词和HMM模式对比
print(' '.join(jieba.cut(s, cut_all = True)))
print(' '.join(jieba.cut(s, cut_all = False, HMM=False)))
结果:
----全模式:----
华为 合作 合作伙伴 伙伴 网络 是 华为 与 合作 合作伙伴 伙伴 之间 的 协作 框架 包含 一系 一系列 系列 的 合作 合作伙伴 伙伴 计划
华为 合作伙伴 网络 是 华为 与 合作伙伴 之间 的 协作 框架 , 包含 一系列 的 合作伙伴 计划 。
5.4.文本文件分词
代码:
# 文本分词
old_file = "../data/华为.txt"
new_file = "../data/华为cut.txt"
# 读取数据
with open(old_file, 'r') as f:
text = f.read()
# 分词
new_text = jieba.cut(text, cut_all=False)
# 去掉标点符号
str_out = ' '.join(new_text).replace(',', '').replace('。', '').replace('?', '').replace('!', '').replace('“', '').replace('”', '').replace(':','').replace('…', '').replace('(', '').replace(')', '').replace('—', '').replace('《', '').replace('》', '').replace('、', '').replace('‘', '').replace('’', '').replace('-', '').replace('\n', '')
# 数据写入和保存
With open(new_file, 'w', encoding='utf-8') as fo:
fo.write(str_out)
# 结果查看
with open(new_file, "r", encoding="utf-8") as f:
print(f.readline(1000))
结果:
公司简介 华为 是 全球 领先 的 ICT 信息 与 通信 基础设施 和 智能 终端 提供商 致力于 把 数字 世界 带入 每个 人 每个 家庭 每个 组织 构建 万物 互联 的 智能 世界 我们 在 通信 网络 IT 智能 终端 和 云 服务 等 领域 为 客户 提供 有 竞争力 安全 可信赖 的 产品 解决方案 与 服务 与 生态 伙伴 开放 合作 持续 为 客户 创造 价值 释放 个人 潜能 丰富 家庭 生活 激发 组织 创新 华为 坚持 围绕 客户 需求 持续 创新 加大 基础 研究 投入 厚积薄发 推动 世界 进步 华为 成立 于 1987 年 是 一家 由 员工 持有 全部 股份 的 民营企业 目前 有 18 万 员工 业务 遍及 170 多个 国家 和 地区 我们 为 世界 带来 了 什么 为 客户 创造 价值 华为 和 运营商 一起 在 全球 建设 了 1 , 500 多张 网络 帮助 世界 超过 三分之一 的 人口 实现 联接 华为 携手 合作伙伴 为 政府 及 公共事业 机构 金融 能源 交通 制造 等 企业 客户 提供 开放 灵活 安全 的 端 管云 协同 ICT 基础设施 平台 推动 行业 数字化 转型 ; 为云 服务 客户 提供 稳定 可靠 安全 可信 和 可 持续 演进 的 云 服务 华为 智能 终端 和 智能手机 正在 帮助 人们 享受 高品质 的 数字 工作 生活 和 娱乐 体验 推动 产业 良性 发展 华为 主张 开放 合作 共赢 与 客户 合作伙伴 及友商 合作 创新 扩大 产业 价值 形成 健康 良性 的 产业 生态系统 华为 加入 360 多个 标准 组织 产业 联盟 和 开源 社区 积极参与 和 支持 主流 标准 的 制定 构建 共 赢 的 生态圈 我们 面向 云 计算 NFV / SDN 5G 等 新兴 热点 领域 与 产业 伙伴 分工协作 推动 产业 持续 良性 发展 促进 经济 增长 华为 不仅 为 所在 国家 带来 直接 的 税收 贡献 促进 当地 就业 形成 产业链 带动 效应 更 重要 的 是 通过 创新 的 ICT 解决方案 打造 数字化 引擎 推动 各行各业 数字化 转
6.实验小结
本章主要是基于中文分词框架jieba进行多种jieba分词模式的演练和操作,由于每种模式的分词效果各不相同,所以可以根据不同的需求进行相应模式的选择。
上一篇: 大数据培训_Kafka 组件的介绍
下一篇: 大数据培训_容量调度器的介绍

微信

公众号











