

发布时间: 2017-07-26 13:28:14
近年来,Python 在数据科学行业扮演着越来越重要的角色。因此,腾科小编在本文中列出了对数据科学家、工程师们最有用的那些库。
核心库
1. NumPy
当开始处理Python中的科学任务,Python的SciPy Stack肯定可以提供帮助,它是专门为Python中科学计算而设计的软件集合。然而,SciPy Stack相当庞大,其中有十几个库,我们把焦点放在核心包上。关于建立科学计算栈,最基本的包是Numpy(Numerical Python)。它为Python中的n维数组和矩阵的操作提供了大量有用的功能。该库提供了NumPy数组类型的数学运算向量化,可以改善性能,从而加快执行速度。
2. SciPy
SciPy是一个工程和科学软件库。SciPy包含线性代数,优化,集成和统计的模块。SciPy库的主要功能是建立在NumPy上,从而它的数组大量的使用了NumPy的。它通过其特定子模块提供有效的数值例程,并作为数字积分、优化和其他例程。
3. Pandas
Pandas是一个Python包,旨在通过“标记”和“关系”数据进行工作,简单直观。Pandas是数据整理的完美工具。它设计用于快速简单的数据操作,聚合和可视化。库中有两个主要的数据结构:
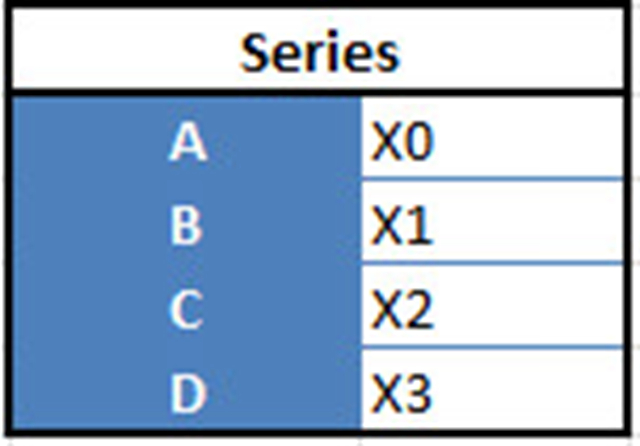
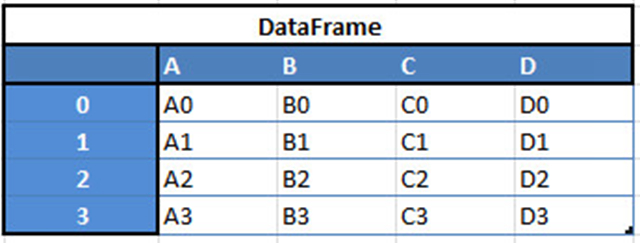
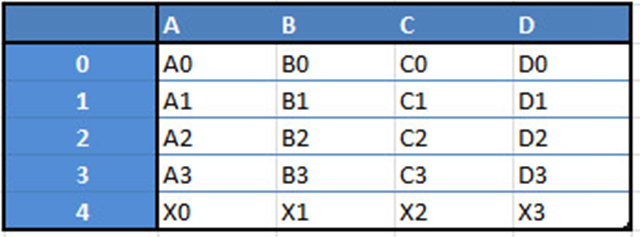
例如,当你要从这两种类型的结构中接收到一个新的Dataframe时,通过传递一个Series,将收到一个单独的行到DataFrame的DF:
这里稍微列出了你可以用Pandas做的事情:
可视化
4.Matplotlib
又一个SciPy Stack核心软件包以及 Python库,Matplotlib为轻松生成简单而强大的可视化而量身定制。它是一个顶尖的软件,它使Python成为像MatLab或Mathematica这样的科学工具的竞争对手。然而,这个库是低层级的,这意味着你需要编写更多的代码才能达到高级的可视化效果,而且通常会比使用更多的高级工具付出更多的努力,但总体上这些努力是值得的。只要付出一点你就可以做任何可视化:
还有使用Matplotlib创建标签,网格,图例和许多其他格式化实体的功能。基本上,一切都是可定制的。该库由不同的平台支持,并使用不同的GUI套件来描述所得到的可视化。不同的IDE(如IPython)都支持Matplotlib的功能。还有一些额外的库可以使可视化变得更加容易。
5. Seaborn
Seaborn主要关注统计模型的可视化;这种可视化包括热图,这些热图总结数据但仍描绘整体分布。Seaborn基于Matplotlib,并高度依赖于此。
6. Bokeh
另一个很不错的可视化库是Bokeh,它针对交互式可视化。与以前的库相比,它独立于Matplotlib。正如我们提到的,Bokeh的主要焦点是交互性,它通过现代浏览器以数据驱动文档(d3.js)的风格呈现。
7. Plotly
它是一个基于Web用于构建可视化的工具箱,提供API给一些编程语言(Python在内)。在plot.ly网站上有一些强大的、上手即用的图形。为了使用Plotly,你将需要设置API密钥。图形将在服务器端处理,并发布到互联网。
机器学习
8. SciKit-Learn
Scikits是Scikits Stack额外的软件包,专为像图像处理和机器学习辅助等特定功能而设计。对于机器学习辅助,scikit-learn是所有软件包里最突出的一个。它建立在SciPy之上,并大量利用它的数学运算。scikit-learn给常见的机器学习算法公开了一个简洁、一致的接口,可简单地将机器学习带入生产系统中。该库中集成了有质量的代码和良好的文档、简单易用并且十分高效,是使用Python进行机器学习的实际行业标准。
9.Theano
Theano是一个Python软件包,它定义了与NumPy类似的多维数组,以及数学运算和表达式。此库是被编译的,可实现在所有架构上的高效运行。最初由蒙特利尔大学机器学习组开发,它主要用于满足机器学习的需求。值得注意的是,Theano紧密结合了NumPy在低层次上的运算 。另外,该库还优化了GPU和CPU的使用,使数据密集型的计算平台性能更佳。
10. TensorFlow
TensorFlow来自Google的开发人员,它是数据流图计算的开源库,为机器学习不断打磨。它旨在满足谷歌对训练神经网络的高需求,并且是基于神经网络的机器学习系统DistBelief的继任者。然而,TensorFlow并不限制于谷歌的科学应用范围,它可以通用于多种多样的现实应用中。
11. Keras
它是一个用Python编写的开源的库,用于在高层的接口上构建神经网络。它简单易懂,具有高级可扩展性。Keras使用Theano或TensorFlow作为后端,但微软现在正努力整合CNTK(微软的认知工具包)作为新的后端。Keras真的容易上手,并在持续完善它的快速原型能力。它完全用Python编写,可被高度模块化和扩展。尽管它以易上手、简单和以高层次为导向,但是Keras足够有深度并且足够强大,去支持复杂的模型。
数据挖掘,统计学
12. Scrapy
Scrapy库是用于从网络结构化检索数据(如联系人信息或URL),可以用来设计crawling程序(也称为蜘蛛bots)。最开始只是如它的名字暗示的一样,只用来做scraping,但是它现在已经在完整的框架中发展,能够从API采集数据并作为通用的crawlers了。该库在界面设计中标榜着“不要重复自己” 它推荐用户们编写泛化得到、可被重复使用的通用代码,从而构建和扩展大型的crawlers。
13. Statsmodels
statsmodels使用户能够通过使用各种统计模型的估算方法进行数据挖掘,并执行统计判断和分析。许多有用的特征是可被描述的,并通过使用线性回归模型、广义线性模型、离散选择模型、鲁棒线性模型、时间序列分析模型,各种估计方法得出统计结果。这个库还提供了广泛的标定功能,专门用于大数据统计中的性能优化工作。
当然,这不是完全详尽的列表,还有许多其他的库和框架同样值得关注。

微信

公众号















