

发布时间: 2021-09-27 16:54:59
历史上,人工智能的概念几经沉浮。如今,凭借低成本的存储、高性能的算力和改进的训练方法,旧的概念再次焕发出新的生机。以TensorFlow和PyTorch为代表的一众深度学习框架的出现,更是将这个领域的门槛降到天下何人不炼丹的程度。
然而,深度学习靠框架,框架还要挑CUDA。
技术的飞速发展和训练框架的野蛮迭代背后,是一地不兼容的版本号,和绕口令一般的困境。

不同的PyTorch版本依赖不同的CUDA版本
不同的TensorFlow版本依赖不同的cuDNN版本
不同的cuDNN版本也依赖不同的CUDA版本
不同的CUDA版本依赖不同的NVIDIAGPU驱动版本
最后不同操作系统的不同版本只支持个别版本的GPU驱动
所以新手最常遇到的场景是,为了运行一份最后更新于三年前的、散发着古早味的、据说很厉害的代码,降级并重装整个操作系统,并且常常因为误信了网上流传的同样古早的二手知识而以失败告终。
基于云的GPU环境一般都会提供预装的镜像,但毕竟选择有限,不能覆盖所有的场景。数据科学家们大多不是工程师,纠缠这些底层细节既不擅长也无意义。工程化的缺失一直是深度学习领域面临的重大问题,年轻的炼丹师们流汗又流泪。
本文将介绍如何基于容器技术快速供给和切换不同的cuDNN/CUDA运行时,轻松搭建不同版本的深度学习环境。
GPU容器化的核心是NVIDIA Container Toolkit:
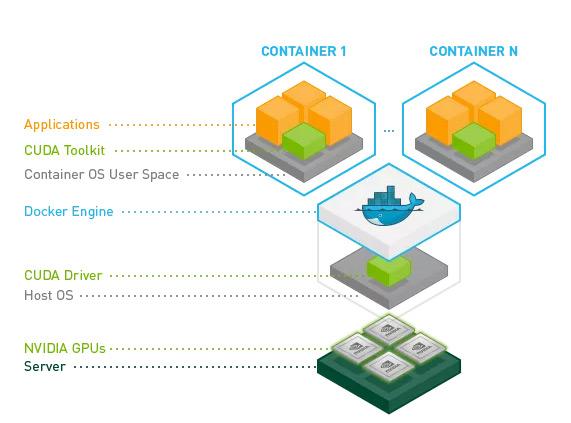
不同的容器共享GPU硬件和驱动,上层的cuDNN/CUDA组件已经预先打包在镜像里,CUDA与底层的驱动和操作系统实现解耦,不同版本的运行时可以在同一台主机上共存,宿主机上只需要安装最新版本的NVIDIA GPU驱动即可。
尽管很宽泛,但是NVIDIAContainer Toolkit对操作系统的发行版和版本号还是有基本的要求:
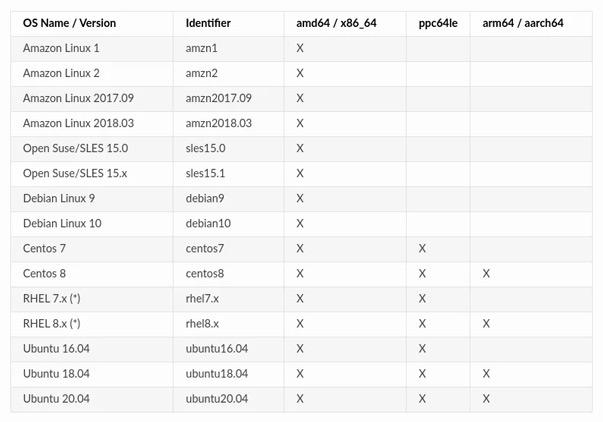
上表中常用的操作系统,Debian过于保守,Ubuntu太过激进,装机量较大的CentOS又前途不明,所以我们选择完全兼容CentOS又有Oracle官方长期支持保障的Oracle Linux作为环境安装的基石,这里使用最新的8.4版本。
首先安装GPU驱动,NVIDIA提供了三种安装方式:本地全量rpm包、网络rpm仓库和二进制可执行文件。毫无疑问应该选择本地全量rpm包,因为旧的依赖包不久就会被从网络上移除,而GPU硬件的使用寿命明显远远长于这些软件,所以不建议选择网络仓库,以免将来无法重新安装;不选择二进制可执行文件是因为安装后难以干净地移除,升级时可能会遇到冲突。
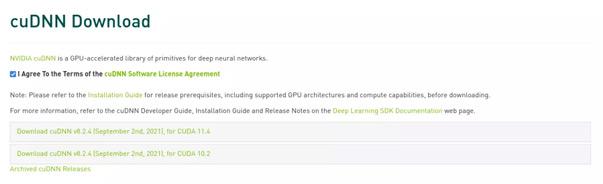
在https://developer.nvidia.com/cuda-downloads下载全量rpm包:

安装内核头文件,注意OracleLinux默认使用的是UEK内核,如果使用主线内核请做相应调整(安装kernel-devel):
【代码】
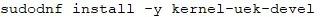
安装驱动模块和必要的依赖:
【代码】

第二步,安装并启动Docker服务:
【代码】

最后,安装NVIDIA Container Toolkit并且重启Docker服务:
【代码】
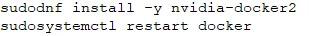
NVIDIA在https://gitlab.com/nvidia/container-images/cuda/blob/master/doc/supported-tags.md提供了从CUDA 9.2到CUDA 11..4.1的多种官方镜像,创建不同版本的cuDNN/CUDA运行时只需要简单拉取对应的镜像即可。
比如安装PyTorch 1.9.0所需的CUDA 10.2:
【代码】
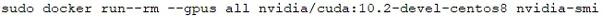
【输出】
不要被右上角的CUDA版本号吓到,它只是表明当前宿主机的GPU驱动所能支持CUDA的最高版本,容器中真正的CUDA版本可以通过nvcc命令来验证:
【代码】
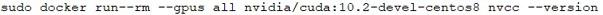
【输出】

祝炼丹成功。
上一篇: 网络工程师女生都做什么

微信

公众号















