人工智能AI培训_Tensorflow 2.0实现手写数字实验
发布时间:
2019-07-18 17:49:14
人工智能AI培训_Tensorflow 2.0实现手写数字实验
1.实验介绍
1.1.关于本实验
本实验主要内容是进行手写字体图像的识别,用到的框架主要包括:TensorFlow2.0,主要用于深度学习算法的构建,本实验以开源的手写字体数据集为基础,基于Keras深度学习库对手写字体进行识别。
1.2.实验目的
理解图像识别的原理。
掌握利用TensorFlow2.0构建图像识别模型。
2.实验步骤
2.1.导入实验环境
步骤 1导入相应的模块
Keras是一个高层神经网络API,Keras由纯Python编写而成并基于Tensorflow、Theano以及CNTK后端。Keras 支持快速实验。
#导入相关依赖包
import os
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets
from matplotlib import pyplot as plt
import numpy as np
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
2.2.导入实验数据集
步骤 2下载数据集
TensorFlow2.0 的datasets中为我们提供了很多开源的数据集,可以直接执行命令下载。
#下载后,我们会得到含有60k的训练集xs,和10k的测试集ys,
(x, y), (x_val, y_val) = datasets.mnist.load_data()
步骤 3数据集格式转换
我们下载得到的数据集是numpy的格式,需要转换成tensor。
#将图像转化为tensor
x = tf.convert_to_tensor(x, dtype=tf.float32) / 255.
y = tf.convert_to_tensor(y, dtype=tf.int32)
print(x.shape, y.shape)
输出结果:
(60000, 28, 28) (60000,)
步骤 4切分训练集与测试集
train_dataset = tf.data.Dataset.from_tensor_slices((x, y))
train_dataset = train_dataset.batch(200)
步骤 5查看数据集信息
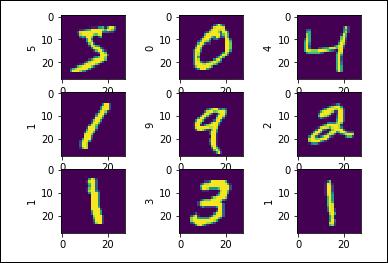
本实验是文字识别,我们可以先打印查看前9张图片,检查图片是否是正确的数据集。
plt.figure()
for i in range(9):
plt.subplot(3,3,i+1)
plt.imshow(x[i])
plt.ylabel(y[i].numpy())
plt.show()
输出结果:
2.3.手写字体图像识别建模
步骤 6初始化神经网络
数据集准备完成,接下来我们就需要构建训练模型,我们首先需要建立初始化的神经网络。
#调用全连接784->512->256->10, 激活函数选择Relu进行映射
model=keras.Sequential([
layers.Dense(512, activation='relu'),
layers.Dense(256, activation='relu'),
layers.Dense(10)
])
步骤 7定义学习率更新规则
设置模型的学习率参数。
#给出学习率(步长)进行更新
optimizer=optimizers.SGD(learning_rate=0.001)
步骤 8构建模型训练函数
神经网络的模型参数更新是一个迭代的过程,所以我们可以将模型训练的过程定义成一个函数,从而进行模型的训练。
def train_epoch(epoch):
# Step4.loop
for step, (x, y) in enumerate(train_dataset):
with tf.GradientTape() as tape:
# 将图像由二维矩阵转化为向量;[b, 28, 28] => [b, 784]
x = tf.reshape(x, (-1, 28*28))
#将label用独热码表示,例5:[0,0,0,0,0,1,0,0,0,0]
y = tf.one_hot(y, depth=10)
# 将图像导入模型开始预测
# [b, 784] => [b, 10]
out = model(x)
# 计算 loss
print(np.size(x))
loss = tf.reduce_sum(tf.square(out - y)) / x.shape[0]
# 更新。optimize and update w1, w2, w3, b1, b2, b3
grads = tape.gradient(loss, model.trainable_variables)
# w' = w - lr * grad
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 == 0:
print(epoch, step, 'loss:', loss.numpy())
return loss
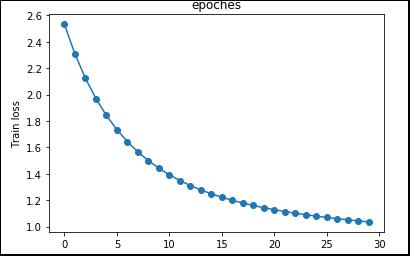
步骤 9构建绘图函数
绘制train loss与epoch的关系图,这样我们就可以查看模型训练的每一步损失值。
def plot_figure(y):
#作出train loss与epoch的关系图
x = range(0, np.size(y))
plt.figure(1)
plt.plot(x, y, 'o-')
plt.title('epoches')
plt.ylabel('Train loss')
plt.show()
步骤 10构建模型训练函数
定义模型训练函数用于进行模型训练:
def train():
#创建list用于保存loss值
loss_list = []
for epoch in range(30):
loss= train_epoch(epoch)
loss_list.append(loss)
plot_figure(loss_list)
步骤 11执行模型训练
执行定义好的模型训练函数进行模型训练:
if __name__ == '__main__':
train()
输出结果:
展示最后10次的模型训练损失值:
20 0 loss: 1.1279364
156800
21 0 loss: 1.1141373
156800
22 0 loss: 1.1015469
156800
23 0 loss: 1.0899687
156800
24 0 loss: 1.0792384
156800
25 0 loss: 1.0692606
156800
26 0 loss: 1.0599515
156800
27 0 loss: 1.0512612
156800
28 0 loss: 1.0431163
156800
29 0 loss: 1.0354265
train loss与epoch的关系图:
本实验利用网上已有的北京房价数据集预测了北京的房价,实现了TensorFlow的线性回归应用。
上一篇:
大数据培训_基于solr的Hbase秒级查询方案
下一篇:
思科认证体系知识















