大数据培训_Flink业界认可度高的开源流处理引擎
1.Flink定义
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。它的较大亮点是流处理,是业界认可度高的开源流处理引擎。
2.Flink特点
Flink与Storm类似,属于事件驱动型实时流系统。Flink简单地说其实是结合了SparkStreaming处理实时的数据量“大”与Strom毫秒级实时的“快”两者的优点应运而生的认可度高的开源流处理引擎。
有以下四大特点:
- Streaming-first流处理引擎
- Fault-tolerant容错,可靠性,checkpoint
- Scalable可扩展性,1000节点以上
- Performance性能,高吞吐量,低延迟
3.Flink应用场景
Flink最适合的应用场景是低时延的数据处理场景:高并发处理数据,时延毫秒级,且兼具可靠性。
典型应用场景有:
4.Flink关键特性
提供ms级时延的处理能力。
提供异步快照机制,保证所有数据真正只处理一次。
JobManager支持主备模式,保证无单点故障。
TaskManager支持手动水平扩展。
5.Flink与hadoop结合

- Flink能够支持Yarn,能够从HDFS和HBase中获取数据;
- 能够使用所有的Hadoop的格式化输入和输出;
- 能够使用Hadoop原有的Mappers和Reducers,并且能与Flink的操作混合使用;
- 能够更快的运行Hadoop的作业。
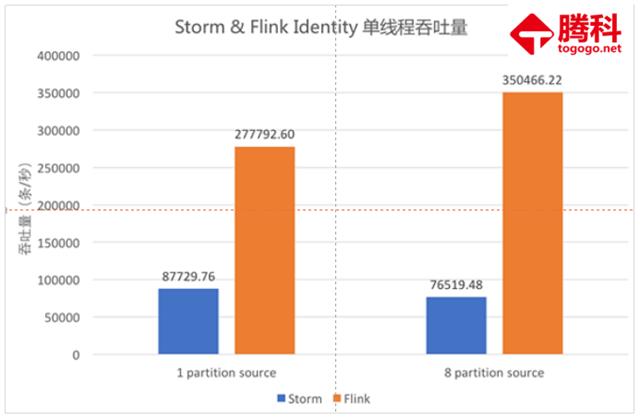
6.Flink与流式计算框架的性能对比
7.Flink架构

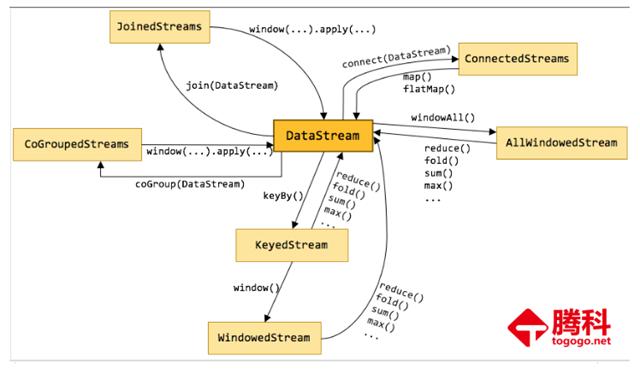
8.Flink核心概念 - DataStream
DataStream:Flink用类DataStream来表示程序中的流式数据。用户可以认为它们是含有重复数据的不可修改的集合(collection),DataStream中元素的数量是无限的。