

发布时间: 2024-05-27 19:55:26
大家学习到了神经网络可以通过逻辑回归之类的算法来对输入进行预测。那么神经网络自己如何判断预测结果是否准确呢? 这一步是非常重要的,因为只有知道自己预测结果是否准确,才能够对自身进行调整,好让结果越来越准确,这就是学习的过程。我们人类学习也应该遵循这个道理,如果一个人一直不停的学,但是不验证自己的学习成果,那么有可能学的方向或学习方法都是错的,不停地学但是结果却都白学了。
那么努力学习 为什么还是考不好?

要验证学习成果,就要判断预测结果是否准确,本篇文章介
绍的损失函数(loss function) 就是干这事的。
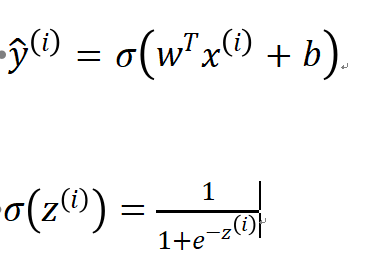
我们先回顾一下上一篇文章中学到的预测算法,如上图。是预测的结果。上面的i角标指代某一个训练样本(本系列教程都会这样来指代某一个训练样本),例如,
是对于训练样本
的预测结果。
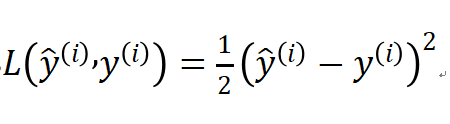
现在,让我们看看可以用什么损失函数来衡量我们的预测算法做得怎么样--判断预测的精准度高不高。损失函数运算后得出的结果越大,那么预测就与实际结果的偏差越大,即预测精度越不高。理论上你可以用上面的公式作为损失函数--预测结果y与实际结果y的差的平方再乘以二分之一。但是在实践中人们通常不会用它,具体为什么,后面的文章再给大家讲解,现在讲了你们也理解不了。实践中我们使用的损失函数的公式如下
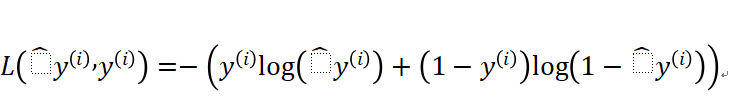
前面的“差平方”公式比较直接,就是 y^越接近有,那么运算得出的结果就越小,那么就说明预测越准确,即损失越小。努力使损失函数的值越小就是努力让预测的结果越准确。其实这个新的损失函数的作用是一样的。具体数学上面的细节我就不讲解了,因为文章的目的是让大家明白人工智能的原理,学会如何实现人工智能。实现一个原理的具体数学公式
是很多的,就像做菜,你明白了它的基本原理后,你可以用各种手段把菜做出来,你可以按照网上的教程做,你也可以自己创造新的做法。对于一些数学当前不好的同学,完全不用怕,因为这些算法都是公开的,而且都有现成的代码可以直接用。后面会给大家展示。
上面对单个训练样本我们定义了损失函数。下面的公式用于衡量预测算法对整个训练集的预测精度。其实就是对每个样本的“损失”进行累加,然后求平均值。这种针对于整个训练集的损失函数我们称它为成本函数 (cost function) 。它的计算结果越大,说明成本越大,即预测越不准确。
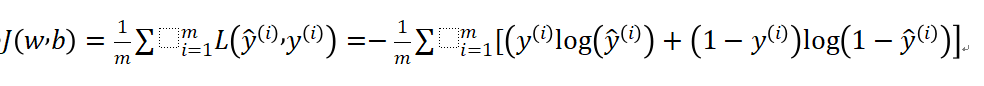
损失函数从严格定义上来讲是(通常严格定义都比较难懂,
不懂不要紧,懂了上面的内容就可以了) :将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。在应用中,损失函数通常作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估模型。
损失函数是机器学习里最基础也是最为关键的一个要素,通过对损失函数的定义、优化,就可以衍生到我们现在常用的机器学习等算法中。
损失函数的作用就是衡量模型模型预测的好坏。再简单一点说就是:损失函数就是用来表现预测与实际数据的差距程度。换一种说法就是衡量两个分布之间的距离:其中一个分布应当是原始分布,或者正确的分布(ground truth),而另一个分布则是目前的分布,或者模型拟合的分布(prediction)。
损失函数是可以很好的反映模型与实际数据差距的工具,理解损失函数能够更好的对后续优化工具(梯度下降等) 进行分析与理解。很多时候遇到复杂的问题时,其实最难的一关是如何写出合适的损失函数。
下一篇: harmonyOS之相机开发

微信

公众号




