

发布时间: 2023-07-26 13:27:10
HBase是Apache Hadoop生态系统中的一个开源、分布式、可扩展的NoSQL数据库。随着大数据应用需求的不断增长,HBase在存储和处理海量数据方面扮演着重要角色。为了高效地使用HBase,需要对HBase进行性能优化。HBase性能优化的常用方法如下。
1.API性能优化
用户通过客户端使用API读写数据时,可以采用以下方法对HBase进行性能优化。
(1)关闭自动刷新写入
使用setAutoFlush(boolean autoFlush)方法,关闭HBase表的自动刷新写入功能。setAutoFlush(boolean autoFlush)方法源代码如下图所示,这是HTable类里的一个成员方法,调用该方法时直接传入布尔类型的false作为其参数即可,即HTable.setAutoFlush(false)。

向HBase表中大量写入数据(进行put操作)时,如果关闭自动自动刷新写入功能,写入的数据会先存放到一个缓冲区,当缓冲区被填满后再传送到HRegion服务器。如果启动了自动功能,每进行一次put操作都会将数据传送到HRegion服务器,会增加网络负载。
(2)设置扫描范围
在使用扫描器处理大量的数据时,可以设置扫描指定的列数据,避免扫描未使用的数据,减少内存开销。
查看一个列族的数据
scan '表名',{NAME=>'列族'}
查看多个列族的数据
scan '表名',{COLUMNS=>['列族1','列族2',’列族n’]}
指定行键范围(包前不包后)
scan '表名',{STARTROW=>'行键1',ENDROW='行键2'}
查询表中时间戳指定范围的数据
scan'user',{TIMERANGE=>[16066740234, 16066740996]}
对于API操作,在实际开发生产中,通常会把查询数据的相关代码封装成一个额外的独立的方法,对应处理相关数据,具体代码示例如下:
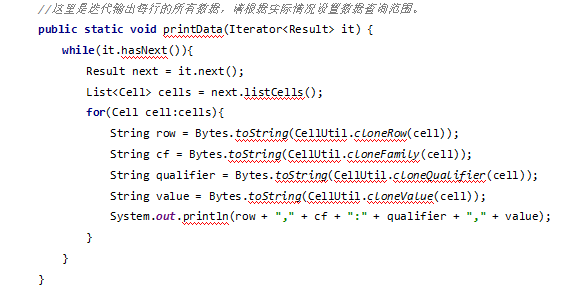
(3)关闭ResultScanner
通过扫描器获取数据后,关闭ResultScanner,这样可以尽快释放对应的HRegionServer的资源。
ResultScanner类用于存储服务端扫描的最终结果,可以通过遍历该类获取查询结果。但是,如果不关闭该类,可能会出现服务端在一段时间内一直保存连接,资源无法释放,从而导致服务器端某些资源的不可用,还有可能引发RegionServer的其他问题。所以在使用完该类之后,需要执行关闭操作。这一点与JDBC操作MySQL类似,需要关闭连接。代码的最后一行rsScanner.close()就是执行关闭ResultScanner。
(4)使用过滤器
使用过滤器过滤出需要的数据,尽量减少服务器通过网络返回到客户端的数据量。
行键前缀过滤器(行键以什么开头)
scan '表名',{FILTER=>"PrefixFilter('值')"}
列过滤器(列标识符中含有值)
scan '表名',{FILTER=>"QualifierFilter(=,'substring:值')"}
列前缀过滤器
scan '表名',{FILTER=>"ColumnprefixFilter('值')"}
值过滤器
scan '表名',{FILTER=>"ValueFilter(=,'substring:值')"}
API操作
对于过滤器的API操作代码部分较多,有兴趣的话可以自信百度。
(5)批量写数据
通过调用HTable.put(Put)方法只能将一个指定的行键记录写入HBase,而通过调用HTable.put(List)方法可以将指定的行键列表,批量写入多行记录,减少网络I/O开销。
2.优化配置
(1)增加处理数据的线程数
在hbase安装目录下的/hbase/conf/hbase-site.xml文件中设置HRegionServer处理I/O请求的线程数,即设置hbase.regionserver.handler.count,该默认值为10。具体如下。

该线程数通常的设置范围为100~200,可以提高HRegionServer的性能。需要注意的是,当数据量很大时,如果该值设置过大,则HBase处理的数据会占用较多的内存,因此该值不是越大越好。
(2)增加堆内存
在hbase安装目录下的/hbase/conf/hbase-env.sh文件中修改堆内存的大小,可以根据实际情况增加堆内存。

(3)调整HRegion的大小
在hbase安装目录下的/hbase/conf/hbase-site.xml文件中修改HRegion的大小。

通常HBase使用较少的HRegion,可以使HBase集群更加平稳地运行;使用较大的HRegion,能够减少HBase集群的HRegion数量。HBase中HRegion的默认大小是256MB,用户可以配置1GB以上的HRegion。
(4)调整堆中块缓存大小
在hbase安装目录下的/hbase/conf/hbase-site.xml文件中修改块缓存大小。

该参数的默认值是0.2,适当增大堆中块缓存可以提高HBase读取大量数据时的效率。
(5)调整Memstore大小
在hbase安装目录下的/hbase/conf/hbase-site.xml文件中修改Memstore大小,设置最大memstore,默认为堆内存的40%(0.4)。

设置最小memstore,默认为最大memstore的95%。

3.其他配置优化建议
(1)使用本地读取
在HBase集群中,如果有足够的本地存储空间,可以将HBase表存储在本地磁盘上而不是HDFS上,以减少数据访问的网络开销。
(2)使用压缩
启用HBase内置的数据压缩功能,可以减少数据存储空间,降低IO负载,提高查询性能。
(3)定期监控与调整
性能优化是一个动态的过程,需要定期监控HBase集群的性能指标,并根据实际情况调整配置参数以保持最佳性能。
4.总结
以上优化配置建议只是一些常见的方案,实际应用中需要根据具体的HBase集群配置和负载情况进行适当调整。在进行任何优化配置之前,建议备份配置文件,以防止配置错误导致集群故障。

微信

公众号










