学员中心登录
IT猎户网
IT就业网
博睿云
IT易学网
营运协同系统
联系我们
18922156670
English
集团站
切换校区
广州
深圳
全部课程
网络技术
华为
HCIA-Datacom
HCIP-Datacom
HCIE-Datacom
思科
CCNA-EI
CCNP-EI
CCIE-EI
系统运维
华为
HCIA-openEuler
HCIP-openEuler
HCIE-openEuler
红帽
RHCSA
RHCE
RHCA
麒麟
KYCA
KYCP
Kubernetes
CKA
CKS
Datacom
/
Security
/
Storage
/
Big-Data
/
Cloud
/
DC
/
UC
/
R&S
/
WLAN
/
Transmission
/
AI
/
IOT
/
GaussDB
/
Kunpeng
HCIP
Datacom
/
R&S
/
Security
/
Storage
/
Big-Data
/
Cloud
/
DC
/
UC
/
WLAN
/
Transmission
/
IOT
AI
HCIE
Datacom
/
R&S
/
Security
/
Storage
/
Big-Data
/
Cloud
/
DC
/
UC
/
WlAN
/
Transmission
数据库
华为
HCIA-openGauss
HCIP-openGauss
HCIE-openGauss
Oracle
OCP
OCM
MySQL
PostgreSQL
PGCA
PGCE
PGCM
TIDB
PCTA
PCTP
人大金仓
KCA
KCP
KCM
云计算
华为
HCIA
Cloud
/
Cloud Service
HCIP
Cloud
/
Cloud Service
HCIE
Cloud
/
Cloud Service
阿里云
ACA
ACP
ACE
腾讯云
TCCA
TCCP
TCCE
亚马逊云
SAA
SAP
安全
华为
HCIA-Security
HCIP-Security
HCIE-Security
CISP
CISP
CISP-PTE
CISP-DSG
CISSP
大数据
华为
HCIA-BigData
HCIP-BigData
HCIE-BigData
人工智能
华为
HCIA-AI
HCIP-AI
项目管理
PMP
ITIL
ITSS
软件开发
鸿蒙
鸿蒙OS移动应用开发
Java
Java高级软件工程师
HTML5
HTML5高级前端工程师
其他
VMware
VCP
技能等级证书
首页
优选课程
华为认证
红帽认证
甲骨文认证
JAVA认证
UI认证
HTML5认证
python认证
思科认证
职业技能等级证书
红帽培训订阅
高校合作
合作理念
合作院校
合作形式
案例分析
企业定制
服务理念
服务内容
服务特色
服务流程
案例汇集
合作名企
考试中心
热门认证考试
预约考试
官方授权考试服务
考场环境
考试流程
考试资讯
学习资源
学习文章
学习视频
关于我们
企业介绍
企业文化
企业环境
密码登录
验证码登录
获取验证码
验证码已发送,请查收短信
微信
电话
复制成功
微信号:
togogoi
添加微信好友, 详细了解课程
已复制成功,如果自动跳转微信失败,请前往微信添加好友
打开微信
新闻资讯
腾科动态
腾科新闻
业界新闻
考试资讯
业界新闻
当前位置:
首页
> >
业界新闻
> >
k-Means聚类
发布时间:
2022-05-17 14:50:44
k-Means聚类
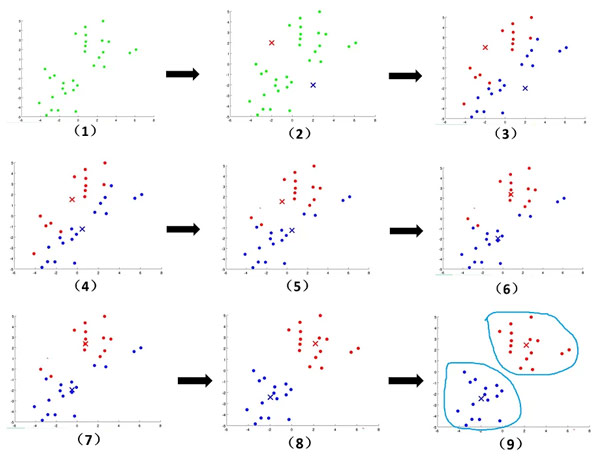
1)k-Means聚类算法原理k-Means算法接受参数k,然后将事先输入的n个数据对象划分为k个聚类以便使所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。
聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
k-Means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。k-Means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近它们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
假设要把样本集分为c个类别,算法描述如下:
① 适当选择c个类的初始中心;
② 在第k次迭代中,对任意一个样本,求其到c个中心的距离,将该样本归到距离最短的中心所在的类;
③ 利用均值等方法更新该类的中心值;
④ 对于所有的c个聚类中心,如果利用②及③的迭代法更新后其值保持不变,则迭代结束,否则继续迭代。
该算法的较大优势在于简洁和快速。算法的关键在于初始中心的选择和距离公式。
2)k-Means聚类算法的实现
k-Means聚类算法的实现步骤如下。
(1)参数input指定待聚类的所有数据点,clusters指定初始聚类中心。如果指定参数k,由org.apache.mahout.clustering.kmeans.RandomSeedGenerator.buildRandom通过org.apache. hadoop.fs直接从input指定文件中随机读取k个点放入clusters中。
(2)根据原数据点和上一次迭代(或初始聚类)的聚类中心计算本次迭代的聚类中心,输出到clusters-N目录下。该过程由org.apache.mahout.clustering.kmeans下的KMeansMapper\KMeansCombiner\KMeansReducer\KMeansDriver实现。
① KMeansMapper:在configure中初始化mapper时读入上一次迭代产生或初始聚类中心(每个mapper都读入所有的聚类中心)。map方法对输入的每个点都计算其最近的距离类,并加入输出的key为该点所属聚类ID,value为KMeansInfo实例,包含点的个数和各分量的累加和。
② KMeansCombiner:本地累加KMeansMapper输出的同一聚类ID下的点个数和各分量的和。
③ KMeansReducer:累加同一聚类ID下的点个数和各分量的和,求本次迭代的聚类中心,并根据输入Delta判断该聚类是否已收敛。上一次迭代聚类中心与本次迭代聚类中心距离小于Delta。输出各聚类中心和其是否收敛标记。
④ KMeansDriver:控制迭代过程直至超过较大迭代次数或所有聚类都已收敛每轮迭代后,KMeansDriver读取其clusters-N目录下的所有聚类。若所有聚类已收敛,则整个k-Means聚类过程收敛了。
3)k-Means聚类算法参数调整
manhout kmeans聚类有两个重要参数,即收敛Delta和较大迭代次数。通常情况下,Delta值越小,表示收敛条件越高,因此最终收敛的聚类数可能会降低,而较大迭代次数可通过观察每次迭代后收敛聚类数决定,当收敛聚类数几乎不再变化或振荡时可停止迭代。
您可能也喜欢:
刚入行学IT?华为认证哪个方向最适合你?
HCIA考试必看:高效选择题解题技巧!
PMP考试可以自己报名吗?
什么是“信创认证”?考试时间、报名条件
3 月 1 日 TiDB 社区活动在深圳!一起聊聊大规模 TiDB 国产化替代在金融、跨境电商等行业的最新实践!
分享到:
QQ空间
新浪微博
腾讯微博
人人网
微信
更多
上一篇:
谱聚类算法
下一篇:
Canopy聚类
相关课程推荐
华为认证
红帽认证
Oracle认证
思科认证
oracle认证ocp培训课程
oracle考试培训
红帽linux培训班
红帽rhcsa认证
华为hcie题库
十八年老品牌
微信咨询:gz_togogo
咨询电话:18922156670
咨询网站客服:
在线客服
点击QQ咨询
电话18922156670
在线咨询
在线咨询
×
您好,请问有什么可以帮您?我们将竭诚提供最优质服务!
QQ咨询
下次再说