

发布时间: 2022-03-09 17:16:37
怎么安装Spark?Spark支持很多版本,目前主流的是1.6.0版本,为了便于学习先下载预编译版本,访问http://spark.apache.org选择Download命令,之后进入下载界面。
在Choose a Spark release下拉列表框中选择1.6.0版本,这是最新的稳定版本。在Choose a package type下拉列表框中选择Pre-built for Hadoop 2.6 andlater选项。这里选择源代码版本或预编译版本,由于之前安装的Hadoop为2.6版本,这里选择此项,读者可以根据实际环境进行选择。
在Choose a downloadtype下拉列表框中选择Direct Download选项直接进行下载,之后单击出现的链接地址就可以下载了。下载界面如图1所示。
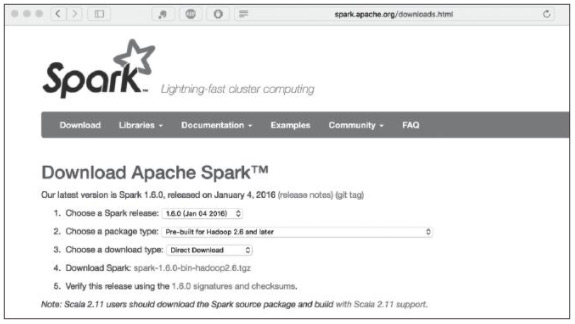
图1 下载界面
此外还需要下载Scala:访问http://www.scala-lang.org/download/下载最新的稳定版本,下载位置如图2所示。
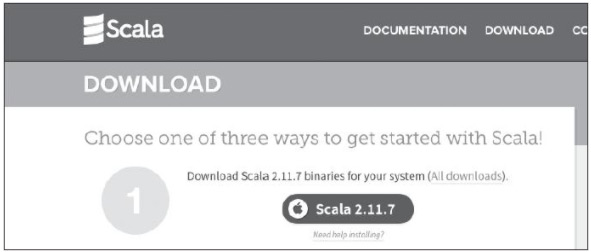
图2 Scala下载位置
环境准备
由于Spark是采用Scala语言编写的,因此需要在Java虚拟机(JVM)上面运行,为了更好地兼容其他的大数据软件,这里建议至少在Java 7版本以上,如果需要进行Scala和Python的开发,需要安装Scala和Python的解释器(Python解释器安装方法请参考附录)。
首先要确保Java环境变量存在,同上一节Hadoop配置,确保/etc/bashrc存在以下代码行:

3.安装
将Scala安装到/opt目录,使用命令如下:

安装完成后,需要设置环境变量。确保以下配置在/etc/bashrc文件中存在:

安装Spark命令如下:

将Spark安装目录设置为环境变量加入/etc/bashrc文件,命令如下:

上一篇: 分布式列存储框架
下一篇: Spark框架

微信

公众号















