

发布时间: 2023-01-06 14:56:52
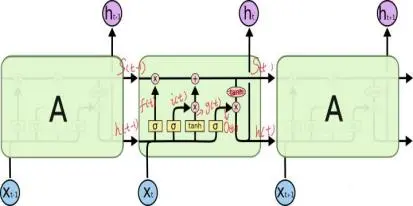
可以看到中间的 cell 里面有四个黄色小框:
-- 每一个小黄框代表一个前馈网络层,其实就是经典的神经网络的结构
-- 这个cell神经元个数和隐藏层个数皆可以设置
-- 其中1、2、4层的**函数是 sigmoid,第三层的**函数是 tanh。
1)、cell 的状态是一个向量,是有多个值的
-- cell在t时刻的状态即是ht
-- 上一层的状态h_t-1 会和当前层的输入xt结合
-- s(t)代表长期记忆,即是前面所有层的作用结果
-- h(t)是短期记忆,即是当前层的状态
2)、上一次的状态 h(t-1)是怎么和下一次的输入 x(t) 结合
-- 很简单,concat,也即是拼接起来
-- 直白的说就是把二者直接拼起来,比如 x是28位的向量,h(t-1)是128位的,那么拼起来就是156位的向量
3)、cell 的权重是共享的
-- 意思是这张图看起来有三个cell,其实只是一个cell的的3个状态;一个状态是一个时间步,每个时间步有一个输入,这个输入由LSTM自动适配
4)、一层的 LSTM 的参数有多少个
-- 一层即是只有一个 cell,所以参数的数量就是这个 cell 里面用到的参数个数。
-- 假设 num_units 是128,输入是28位的,那么根据上面的第 2 点,可以得到,四个小黄框的参数一共有 (128+28)*(128*4),也就是156 * 512
-- 可以看看 TensorFlow 的最简单的 LSTM 的案例,中间层的参数就是这样
-- 不过还要加上输出的时候的**函数的参数,假设是10个类的话,就是128*10的 W 参数和10个bias 参数
怎么产生序列:
-- LSTM如果每个时间步都产生一个结果
-- 即是每基于一个输入和上一个时间就产生一个结果,保留每个结果那不就可以产生一个序列了
怎么用来做普通预测:
-- 最后一层加上全连接网络即可
输入数据的格式为:[样本总数/时间步个数 ,时间步长度,特征长度]
--即整体上要按时间步输入样本批次,一个批次样本的数量 = 样本总数量/时间步
--而具体到x中的每个元素,也要处理为 [时间步长度,特征长度] ,即是每个元素都是 时间步个数 条 样本
更通俗理解:一个单词代表一个timestep
在inference的时候,只能一个单词一个单词地输出;
而在train的时候,我们有整个句子,因此可以一次feed若干个单词(因为有n个timestep)
-- 比如一个训练目标为Google is better than Apple
-- 因为timestep为5,于此同时训练目标为is better than Apple

上一篇: esxi有什么功能
下一篇: dropout层的作用

微信

公众号




