

发布时间: 2018-01-30 16:26:29
1. 什么是hbase
HBASE是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBASE的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBASE是Google Bigtable的开源实现,但是也有很多不同之处。比如:Google Bigtable利用GFS作为其文件存储系统,HBASE利用Hadoop HDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBASE同样利用Hadoop MapReduce来处理HBASE中的海量数据;Google Bigtable利用Chubby作为协同服务,HBASE利用Zookeeper作为对应。
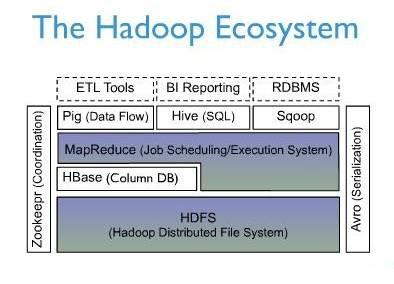
上图描述了Hadoop EcoSystem中的各层系统,其中HBase位于结构化存储层,Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。 此外,Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。 2. 与传统数据库的对比 1、传统数据库遇到的问题: 1)数据量很大的时候无法存储 2)没有很好的备份机制 3)数据达到一定数量开始缓慢,很大的话基本无法支撑 2、HBASE优势: 1)线性扩展,随着数据量增多可以通过节点扩展进行支撑 2)数据存储在hdfs上,备份机制健全 3)通过zookeeper协调查找数据,访问速度块。 3. hbase集群中的角色 1、一个或者多个主节点,Hmaster 2、多个从节点,HregionServer
安装部署Hbase在多台装有hadoop、zookeeper的机器上安装hbase,本课程是以hdp08、hdp09、hdp10三台机器为例子来讲解 1. hdp08、hdp09、hdp10三台机器分别安装JDK、HADOOP、ZOOKEEPER,并设置好环境变量 2. 从Apache网站上(http://hbase.apache.org/)下载HBase稳定发布包,本课程以hbase-1.1.12-bin.tar.gz为例,将hbase-1.1.12-bin.tar.gz上传到hdp08 3. 解压hbase-1.1.12-bin.tar.gz到/home/hadoop/apps目录下 [hadoop@hdp10 ~]$ tar zxvf hbase-1.1.12-bin.tar.gz -C apps 4. 将解压出来的文件夹名称修改成hbase [hadoop@hdp10 apps]$ mv hbase-1.1.12 hbase 5. 设置环境变量 [root@hdp10 apps]# vi /etc/profile JAVA_HOME=/opt/jdk1.8.0_121 ZOOKEEPER_HOME=/home/hadoop/apps/zookeeper HBASE_HOME=/home/hadoop/apps/hbase PATH=$HBASE_HOME/bin:$ZOOKEEPER_HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export HBASE_HOME ZOOKEEPER_HOME HADOOP_HOME JAVA_HOME PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL[root@hdp10 apps]#source /etc/profile [hadoop@hdp10 apps]$ hbase version
7. 编辑$HBASE_HOME/conf/hbase-env.sh [hadoop@hdp08 conf]$ vi hbase-env.sh # #/** # * Copyright 2007 The Apache Software Foundation # * # * Licensed to the Apache Software Foundation (ASF) under one # * or more contributor license agreements. See the NOTICE file # * distributed with this work for additional information # * regarding copyright ownership. The ASF licenses this file # * to you under the Apache License, Version 2.0 (the # * "License"); you may not use this file except in compliance # * with the License. You may obtain a copy of the License at # * # * http://www.apache.org/licenses/LICENSE-2.0 # * # * Unless required by applicable law or agreed to in writing, software # * distributed under the License is distributed on an "AS IS" BASIS, # * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # * See the License for the specific language governing permissions and # * limitations under the License. # */ # Set environment variables here. # This script sets variables multiple times over the course of starting an hbase process, # so try to keep things idempotent unless you want to take an even deeper look # into the startup scripts (bin/hbase, etc.) # The java implementation to use. Java 1.6 required. export JAVA_HOME=/opt/jdk1.8.0_121/ # Extra Java CLASSPATH elements. Optional.这行代码是错的,需要可以修改为下面的形式 #export HBASE_CLASSPATH=/home/hadoop/hbase/conf export JAVA_CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar # The maximum amount of heap to use, in MB. Default is 1000. # export HBASE_HEAPSIZE=1000 # Extra Java runtime options. # Below are what we set by default. May only work with SUN JVM. # For more on why as well as other possible settings, # see http://wiki.apache.org/hadoop/PerformanceTuning export HBASE_OPTS="-XX:+UseConcMarkSweepGC" # Uncomment below to enable java garbage collection logging for the server-side processes # this enables basic gc logging for the server processes to the .out file # export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps $HBASE_GC_OPTS" # this enables gc logging using automatic GC log rolling. Only applies to jdk 1.6.0_34+ and 1.7.0_2+. Either use this set of options or the one above # export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=512M $HBASE_GC_OPTS" # Uncomment below to enable java garbage collection logging for the client processes in the .out file. # export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps $HBASE_GC_OPTS" # Uncomment below (along with above GC logging) to put GC information in its own logfile (will set HBASE_GC_OPTS). # This applies to both the server and client GC options above # export HBASE_USE_GC_LOGFILE=true # Uncomment below if you intend to use the EXPERIMENTAL off heap cache. # export HBASE_OPTS="$HBASE_OPTS -XX:MaxDirectMemorySize=" # Set hbase.offheapcache.percentage in hbase-site.xml to a nonzero value. # Uncomment and adjust to enable JMX exporting # See jmxremote.password and jmxremote.access in $JRE_HOME/lib/management to configure remote password access. # More details at: http://java.sun.com/javase/6/docs/technotes/guides/management/agent.html # # export HBASE_JMX_BASE="-Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false" # export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10101" # export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10102" # export HBASE_THRIFT_OPTS="$HBASE_THRIFT_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10103" # export HBASE_ZOOKEEPER_OPTS="$HBASE_ZOOKEEPER_OPTS $HBASE_JMX_BASE -Dcom.sun.management.jmxremote.port=10104" # File naming hosts on which HRegionServers will run. $HBASE_HOME/conf/regionservers by default. # export HBASE_REGIONSERVERS=${HBASE_HOME}/conf/regionservers # File naming hosts on which backup HMaster will run. $HBASE_HOME/conf/backup-masters by default. # export HBASE_BACKUP_MASTERS=${HBASE_HOME}/conf/backup-masters # Extra ssh options. Empty by default. # export HBASE_SSH_OPTS="-o ConnectTimeout=1 -o SendEnv=HBASE_CONF_DIR" # Where log files are stored. $HBASE_HOME/logs by default. # export HBASE_LOG_DIR=${HBASE_HOME}/logs # Enable remote JDWP debugging of major HBase processes. Meant for Core Developers # export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8070" # export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8071" # export HBASE_THRIFT_OPTS="$HBASE_THRIFT_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8072" # export HBASE_ZOOKEEPER_OPTS="$HBASE_ZOOKEEPER_OPTS -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8073" # A string representing this instance of hbase. $USER by default. # export HBASE_IDENT_STRING=$USER # The scheduling priority for daemon processes. See 'man nice'. # export HBASE_NICENESS=10 # The directory where pid files are stored. /tmp by default. # export HBASE_PID_DIR=/var/hadoop/pids # Seconds to sleep between slave commands. Unset by default. This # can be useful in large clusters, where, e.g., slave rsyncs can # otherwise arrive faster than the master can service them. # export HBASE_SLAVE_SLEEP=0.1 # Tell HBase whether it should manage it's own instance of Zookeeper or not. export HBASE_MANAGES_ZK=false 8. 编辑hbase-site.xml [hadoop@hdp08 conf]$ vi hbase-site.xml <configuration> <property> <name>hbase.rootdir</name> <value>hdfs://hdp08:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>hdp08:2181,hdp09:2181,hdp10:2181</value> </property> </configuration> 注意:hbase.zookeeper.quorum中的值应当是运行zookeeper的机器 9. 编辑regionservers [hadoop@hdp08 conf]$ vi regionservers hdp09 hdp10 10. 将hdp08的hbase发送到hdp09,hdp10 [hadoop@hdp08 apps]$ scp -r hbase hadoop@hdp09:/home/hadoop/apps [hadoop@hdp08 apps]$ scp -r hbase hadoop@hdp10:/home/hadoop/apps 11. 启动HBase [hadoop@hdp08 apps]$ start-hbase.sh 启动本机hbase [hadoop@hdp08 bin]$ hbase-daemon.sh start master [hadoop@hdp08 bin]$hbase-daemon.sh start regionserver 12. 验证启动 1. 在hadoop节点使用jps查看节点状态 13. 查看启动状态信息 http://192.168.195.138:16010/ 三、 配置多台HMaster 在$HBASE_HOME/conf/ 目录下新增文件配置backup-masters,在其内添加要用做Backup Master的节点hostname。如下: [hadoop@hdp08 conf]$ vi backup-masters dhp09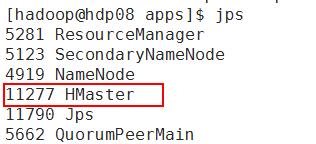
上一篇: {大数据}HBase访问接口
下一篇: {大数据}HIVE基本操作

微信

公众号




